4月16日(火)、17日(水)の2日間にわたって大崎ブライトコアホールおよびオンラインにて開催される「DevOpsDays Tokyo 2024」に岩見彰太が登壇いたします。
DevOpsDays Tokyoとは
世界中で開催されている、ソフトウェア開発、ITインフラ運用、そしてその境界線上にあるトピックを扱うカンファレンスです。特にDevOpsを実現するための自動化やテスト、セキュリティ、組織文化にフォーカスしています。
登壇について
・日時
4月16日(火) 14:25 - 14:45
・スピーカー
AI事業本部所属 岩見彰太
・セッションタイトル
「自動生成を活用した、運用保守コストを抑える Error/Alert/Runbook の一元集約管理」
・詳細
開発を進めていく中で、アラートの適切な設定とそれに対する対処は非常に重要です。未知のエラーや外部の障害に対する検知を取り逃がさず素早く行い、できるだけ初期段階で対処することを心がけるのは、サービスの品質を落とさないために不可欠です。
その中でも特に複数のサービスを連携する必要がある場合、エラーや障害の対応が現場のエンジニアだけで解決するものだけでなく、非エンジニアも含めたビジネス的な判断を迅速に行う必要がある場合が多数存在します。
このような場合、エラーの内容や対処方法の判断を即座に判断できる人をできるだけ増やすことが大切です。例えばアラート通知の文言に分かりやすいエラー内容とそれに対する具体的な対応方法を記載するなどです。
また、特定のエラーの原因や対処方法が実際に実装したエンジニアにしかすぐにわからないといった属人化を減らすことも、ログ調査に要する時間の短縮の観点から重要です。 これらに対処するには、多くの場合以下のような環境を整えることが考えられます。
一般的な HTTP Status Code などとは別に、
・エラー原因を特定できる独自のエラーコードを定義する
・独自のエラーコードとそのエラーの具体的な原因、そのエラーに対する対処方法をドキュメントにまとめる
・エラーが発生した際は、そのエラーコードからドキュメントを参照し対処を行う
しかしこれらにはいくつか問題点が存在します。
・アプリケーション側に埋め込む独自のエラーコードとドキュメントが分散管理されており、保守コストが高いため、メンテナンスが困難になる可能性がある
・エラーが発生した際の通知ではエラーコードしかわからないため、それがどのような意味でどのような行動をすべきかどうかはドキュメントを参照しにいく必要がある
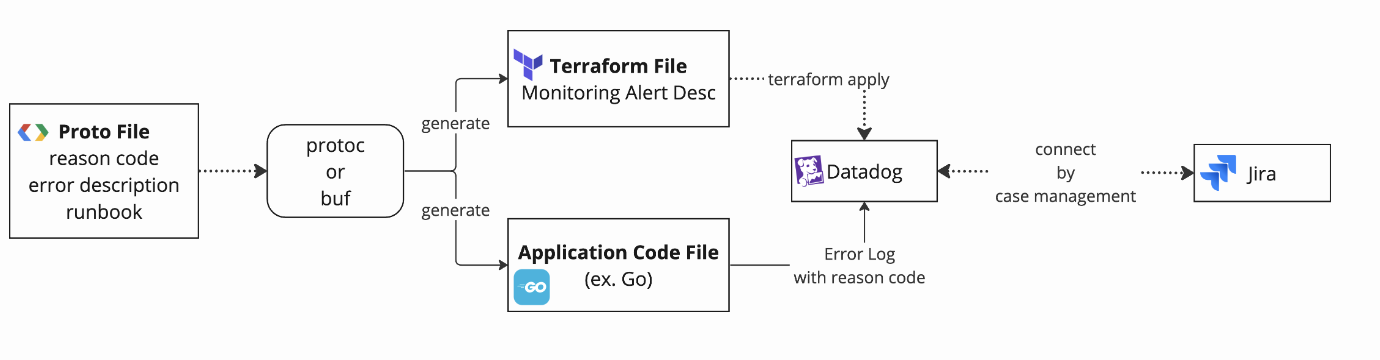
このような背景から、重要であることは分かりつつも運用コストが高くなってしまうという問題がありました。 この問題を解決するために、protoファイルと Protoc プラグインを活用した情報の集約を行い、運用コストを下げる取り組みを行いました。protoファイルに「独自エラーコード(Reason Code)」「エラー内容(Alert)」「対処手順(Runbook)」を記載し、それを元に以下の部分を自動生成しました。
・アプリケーション実装でのエラーコード埋め込み用の実装
・Terraformで管理している Datadog Monitoring Alert 用のアラート文章
この取り組みにより、実装プロセスが大幅に効率化されます。まず、protoファイルに必要な全ての情報を集約して記述します。これによってアプリケーションエラー用のコードとモニタリングアラート用のコードが自動生成されます。結果的に、一つのファイルで情報を一元管理することが可能となり、管理コストを大幅に削減できました。
本セッションでは具体的な自動生成機構の実装方法から、これによって実現できた Error/Alert/Runbook の一元集約管理による恩恵について詳しく説明します。また、実際の運用において、エラーが発生してからそれを検知し、実際にチケットを切って対処を行い解決するまでの流れも説明します。セッションを通じて、オブザーバビリティ周りでの自動生成を活用した際のメリットについてヒントを得ることができます。また、これらのアイデアを応用することで、よりリッチなアラート情報を低コストで提供するアイデアを得ることができます。
4月16日(火) 14:25 - 14:45
・スピーカー
AI事業本部所属 岩見彰太
・セッションタイトル
「自動生成を活用した、運用保守コストを抑える Error/Alert/Runbook の一元集約管理」
・詳細
開発を進めていく中で、アラートの適切な設定とそれに対する対処は非常に重要です。未知のエラーや外部の障害に対する検知を取り逃がさず素早く行い、できるだけ初期段階で対処することを心がけるのは、サービスの品質を落とさないために不可欠です。
その中でも特に複数のサービスを連携する必要がある場合、エラーや障害の対応が現場のエンジニアだけで解決するものだけでなく、非エンジニアも含めたビジネス的な判断を迅速に行う必要がある場合が多数存在します。
このような場合、エラーの内容や対処方法の判断を即座に判断できる人をできるだけ増やすことが大切です。例えばアラート通知の文言に分かりやすいエラー内容とそれに対する具体的な対応方法を記載するなどです。
また、特定のエラーの原因や対処方法が実際に実装したエンジニアにしかすぐにわからないといった属人化を減らすことも、ログ調査に要する時間の短縮の観点から重要です。 これらに対処するには、多くの場合以下のような環境を整えることが考えられます。
一般的な HTTP Status Code などとは別に、
・エラー原因を特定できる独自のエラーコードを定義する
・独自のエラーコードとそのエラーの具体的な原因、そのエラーに対する対処方法をドキュメントにまとめる
・エラーが発生した際は、そのエラーコードからドキュメントを参照し対処を行う
しかしこれらにはいくつか問題点が存在します。
・アプリケーション側に埋め込む独自のエラーコードとドキュメントが分散管理されており、保守コストが高いため、メンテナンスが困難になる可能性がある
・エラーが発生した際の通知ではエラーコードしかわからないため、それがどのような意味でどのような行動をすべきかどうかはドキュメントを参照しにいく必要がある
このような背景から、重要であることは分かりつつも運用コストが高くなってしまうという問題がありました。 この問題を解決するために、protoファイルと Protoc プラグインを活用した情報の集約を行い、運用コストを下げる取り組みを行いました。protoファイルに「独自エラーコード(Reason Code)」「エラー内容(Alert)」「対処手順(Runbook)」を記載し、それを元に以下の部分を自動生成しました。
・アプリケーション実装でのエラーコード埋め込み用の実装
・Terraformで管理している Datadog Monitoring Alert 用のアラート文章
この取り組みにより、実装プロセスが大幅に効率化されます。まず、protoファイルに必要な全ての情報を集約して記述します。これによってアプリケーションエラー用のコードとモニタリングアラート用のコードが自動生成されます。結果的に、一つのファイルで情報を一元管理することが可能となり、管理コストを大幅に削減できました。
本セッションでは具体的な自動生成機構の実装方法から、これによって実現できた Error/Alert/Runbook の一元集約管理による恩恵について詳しく説明します。また、実際の運用において、エラーが発生してからそれを検知し、実際にチケットを切って対処を行い解決するまでの流れも説明します。セッションを通じて、オブザーバビリティ周りでの自動生成を活用した際のメリットについてヒントを得ることができます。また、これらのアイデアを応用することで、よりリッチなアラート情報を低コストで提供するアイデアを得ることができます。