Media Data Tech Studioの自然言語処理チームでは、テキストのバッチ・ストリーミング処理を行う言語処理基盤と、テキストを含む様々なデータを入力とした機械学習システムを開発しています。これらのシステムは、検索・情報推薦・広告をはじめとした様々なサービスの機能を支えています。
テキスト処理基盤
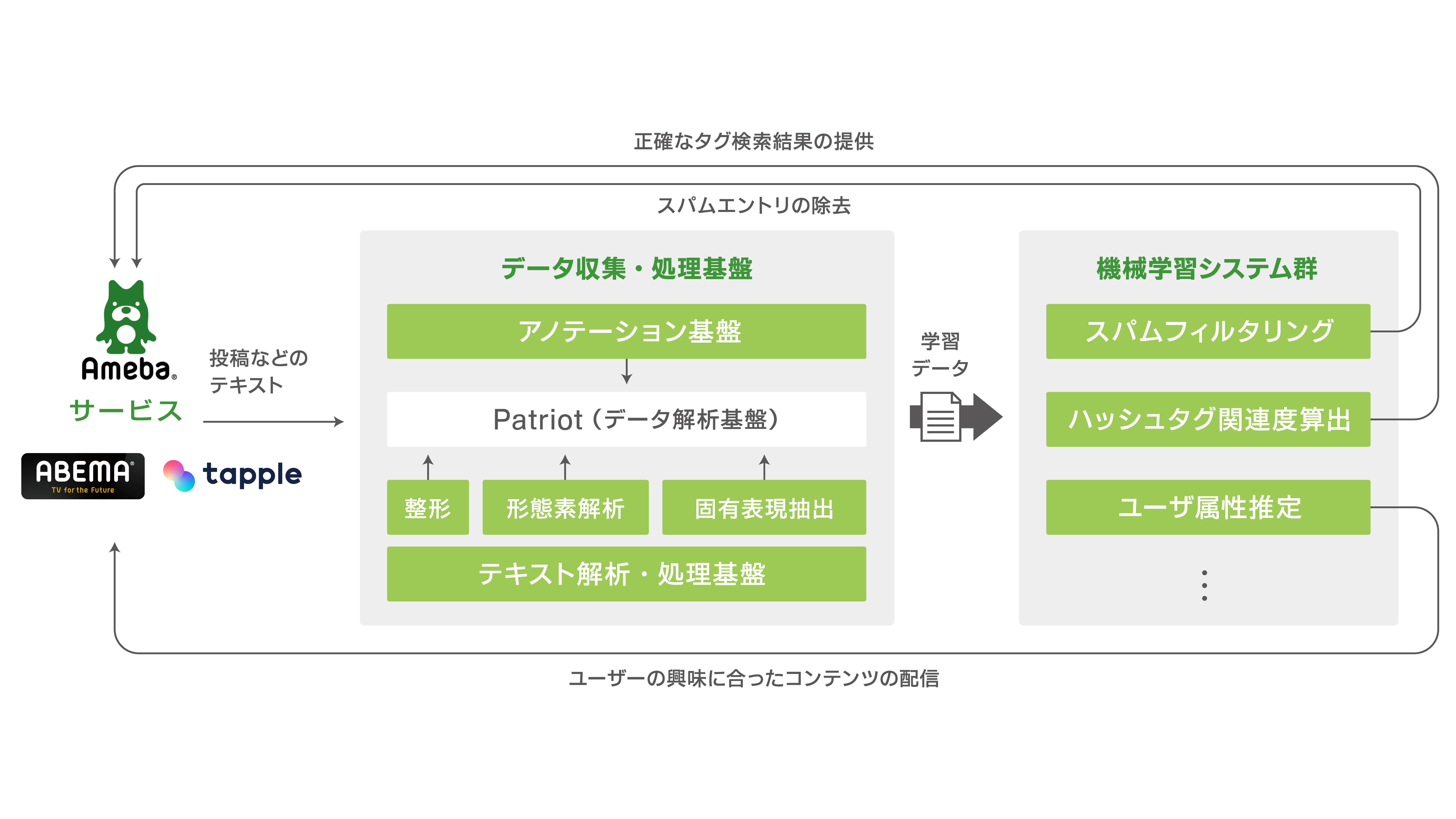
テキスト処理基盤では、ユーザが投稿した記事などのテキストデータをストリームで受け取り、テキスト整形・形態素解析・分散表現ベクトル生成・キーワードの抽出などの前処理を行った上でデータストアに格納します。併せて、格納したデータをリアルタイムで取り出すためのAPIも整備しており、テキスト情報が必要な機械学習システムの開発を容易にしています。
テキストを用いた機械学習
テキストを用いた機械学習は、幅広いサービス要求に応え、ユーザ体験の向上に寄与しています。例えば、Amebaブログなどのサービスでは、ユーザが悪意のある記事に触れることを機械学習フィルタにより防ぐ仕組みを作り運用しています。また、ブログ記事とハッシュタグ関連度算出に基づく検索ランキング、文書の分散表現を特徴量として利用したアイテム推薦や、閲覧ユーザの属性・興味推定などにも自然言語処理の技術が応用されています。これらの仕組みにより、ユーザの意図や興味に沿ったコンテンツの配信が可能となっています。
機械学習システムの核となる技術には、最先端の論文に基づく手法だけでなく、機械学習コンテストで用いられている特徴量エンジニアリングなどの手法を取り入れています。これらの知見に加え、実際にサービスの運用に携わるディレクターやエンジニアから得られたドメイン知識に基づく工夫を取り入れることで、ユーザ体験のさらなる向上を目指しています。
機械学習システムの核となる技術には、最先端の論文に基づく手法だけでなく、機械学習コンテストで用いられている特徴量エンジニアリングなどの手法を取り入れています。これらの知見に加え、実際にサービスの運用に携わるディレクターやエンジニアから得られたドメイン知識に基づく工夫を取り入れることで、ユーザ体験のさらなる向上を目指しています。