現在、インターネット上でサービスを運営する上でデータを活用することの重要性が増しています。データの活用によって、ユーザの行動ログやWeb サイトへのアクセスログを分析することで適切なサービス改善につなげることや、検索・推薦などのサービスの価値を高める機能を実現することができます。また、近年はインターネット上の広告配信などでもデータ活用により品質を向上させることが求められています。
当社ではAmebaブログやAbemaTVなど様々なインターネットサービスを運営しており、それらの改善にデータ活用が重要となっています。例えば、Ameba ブログは国内最大規模のブログサービスであり、当社の提供するサービスは多くのユーザに利用されています。このため関連するデータの量も膨大となり、大規模データを効率的に処理するシステムが必要となります。
Media Data Tech Studioは当社のメディア事業におけるデータの有効活用を目的としており、そのために様々な大規模データ処理システムを開発し、運用しています。大規模データ処理の分野は技術の進歩が著しく、またネットサービスは機能改善などが頻繁に行われます。このような変化の多い環境では、システムの開発から運用までを一貫して行い様々な要件に対して柔軟に適応することが重要と考えます。
大規模データ処理の分野では様々な技術が提案されており、OSS やクラウドサービスとして実装されているものが多く存在します。そこでMedia Data Tech Studioでは最新の OSS の導入や様々なクラウドサービスとの連携を視野にいれてシステム開発を行っています。また、ストリーム処理など要件が多様で標準的な実装が提供されていないものについては、独自のシステムを研究開発し、実用化しています。
当社ではAmebaブログやAbemaTVなど様々なインターネットサービスを運営しており、それらの改善にデータ活用が重要となっています。例えば、Ameba ブログは国内最大規模のブログサービスであり、当社の提供するサービスは多くのユーザに利用されています。このため関連するデータの量も膨大となり、大規模データを効率的に処理するシステムが必要となります。
Media Data Tech Studioは当社のメディア事業におけるデータの有効活用を目的としており、そのために様々な大規模データ処理システムを開発し、運用しています。大規模データ処理の分野は技術の進歩が著しく、またネットサービスは機能改善などが頻繁に行われます。このような変化の多い環境では、システムの開発から運用までを一貫して行い様々な要件に対して柔軟に適応することが重要と考えます。
大規模データ処理の分野では様々な技術が提案されており、OSS やクラウドサービスとして実装されているものが多く存在します。そこでMedia Data Tech Studioでは最新の OSS の導入や様々なクラウドサービスとの連携を視野にいれてシステム開発を行っています。また、ストリーム処理など要件が多様で標準的な実装が提供されていないものについては、独自のシステムを研究開発し、実用化しています。
データ解析基盤「Patriot」の構築・運用
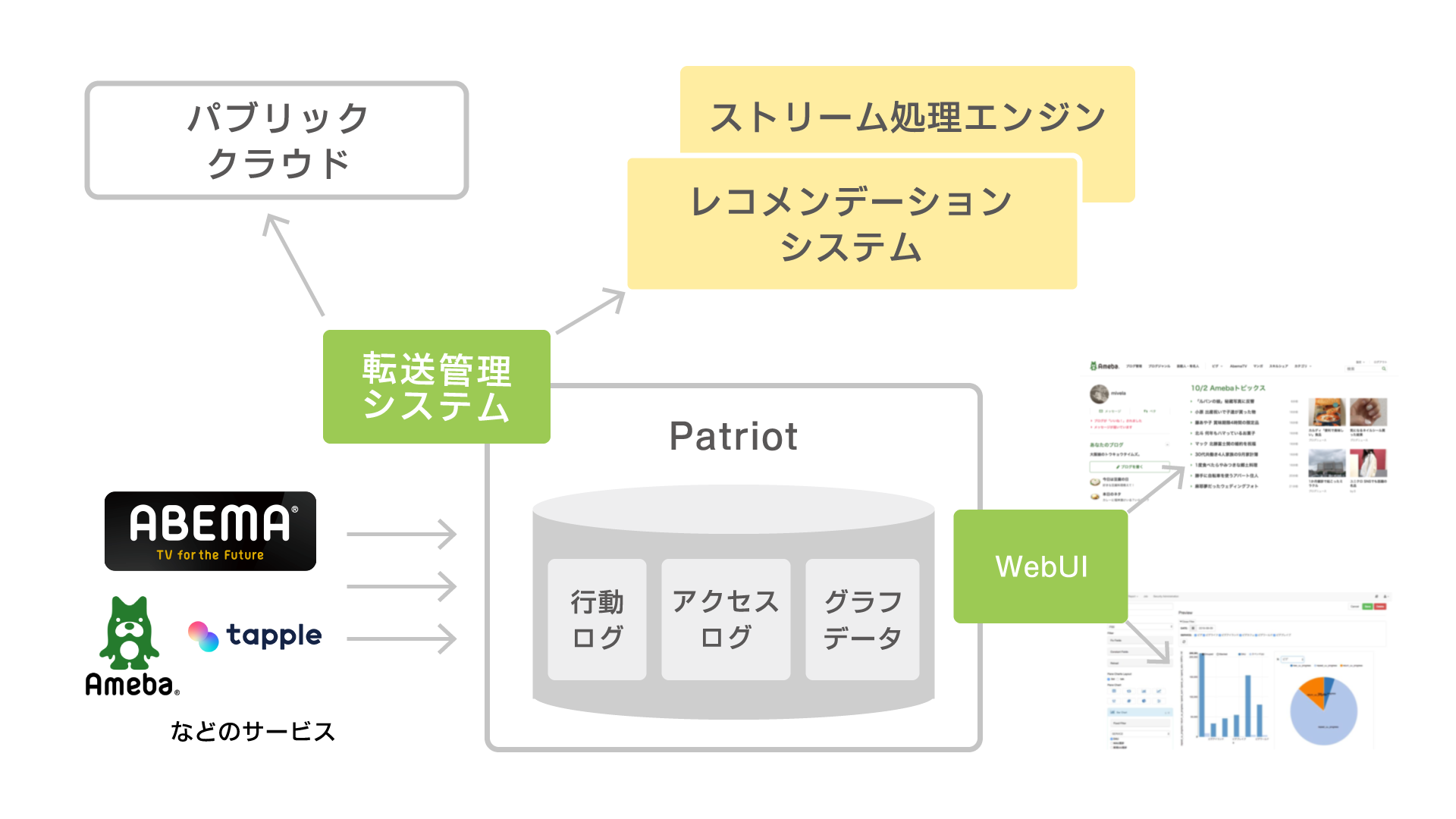
Media Data Tech Studioでは、サイバーエージェントのメディア事業におけるデータ活用のために独自で「Patriot」と呼ばれるデータ処理基盤を開発・運用しています。当社のメディア事業ではAbemaTVやAmebaブログなど多種多様なサービスを提供しています。そのため、サービス利用のログデータは大量に発生し、ユーザーの利用方法や目的が一様ではないため、その利用ログデータは複雑化していきます。このようなデータを有効活用し、ユーザーの皆様がより便利に、快適に様々なサービスをご利用いただけるよう、サービスの状況把握のための各種レポートの生成や、レコメンデーション機能実現のための基盤が必要となり、「Patriot」を自社開発しました。
「Patriot」は、Apache Hadoopなどのオープンソースソフトウェア(OSS)を用いて構築しています。また、パブリッククラウドの連携やKubernetesを用いたコンテナ基盤の開発も行っており、用途に応じた活用方法を環境によらず透過的に提供するための技術開発に取り組んでいます。さらに、複雑化したデータ構造に対応するためのワークフロースケジューラ、データの品質・転送管理や可視化システムなどを独自に実装・導入するなど、分散システムやデータ工学に関する研究開発も行っています。
「Patriot」は、Apache Hadoopなどのオープンソースソフトウェア(OSS)を用いて構築しています。また、パブリッククラウドの連携やKubernetesを用いたコンテナ基盤の開発も行っており、用途に応じた活用方法を環境によらず透過的に提供するための技術開発に取り組んでいます。さらに、複雑化したデータ構造に対応するためのワークフロースケジューラ、データの品質・転送管理や可視化システムなどを独自に実装・導入するなど、分散システムやデータ工学に関する研究開発も行っています。
ストリーム処理エンジン「Zero」の開発・運用
「Zero」はストリーム処理基盤のひとつとして、Media Data Tech Studioで開発・運用を行っています。このシステムは、SQLライクな独自のクエリ言語「ZeroQL」を事前に記述しておくことで、当社が提供する様々なサービスで発生したログをリアルタイムに処理し、データストアに記録するものです。データストアとして主にApache HBaseを利用しており、記録されたデータはAPI経由で数ミリ秒~数十ミリ秒の低いレイテンシで取得でき、レコメンデーション、広告配信、プッシュ通知などの配信制御及び精度向上、また、各種指標のリアルタイムのレポーティングなどに活用されています。

データフローマネジメント
アクセスログや行動ログなどのデータはメディア系の様々なサービスで日々生成されており、これらのデータを有効活用するためには種別・用途に応じて適切なシステムに送り届ける必要があります。データ活用に関連するシステムは、オンプレミスのHadoopクラスタやPrivate/Public Cloud上のシステムなど多様であり、各システムに応じた転送方式をサポートする必要があります。また、サービスやデータの種別によっては、フィルタリングやデータ変換などの前処理が要求されることもあります。
これらの問題を解決するために、Media Data Tech Studioではデータ転送をレイヤ構造として抽象化することで転送処理の共通化、汎用化を実現する取り組みを行っています。
レイヤ化により転送における責務を分離し、ログの構造やセマンティクスの変化が転送経路に影響を及ぼすことを防ぐと共に、転送の仕組みを共通化することで運用の属人化を防ぐ狙いがあります。また、このレイヤ化に則った転送処理を実行するための「Kafon」というデータフロー管理システムの開発を進めています。Kafonはデータの入出力・データの変換・フィルタリングなどのタスクがプラガブルに選択できるストリーム処理基盤となっており、必要なタスクを組み合わせることでデータの転送と前処理を実現することができます。
これらの問題を解決するために、Media Data Tech Studioではデータ転送をレイヤ構造として抽象化することで転送処理の共通化、汎用化を実現する取り組みを行っています。
レイヤ化により転送における責務を分離し、ログの構造やセマンティクスの変化が転送経路に影響を及ぼすことを防ぐと共に、転送の仕組みを共通化することで運用の属人化を防ぐ狙いがあります。また、このレイヤ化に則った転送処理を実行するための「Kafon」というデータフロー管理システムの開発を進めています。Kafonはデータの入出力・データの変換・フィルタリングなどのタスクがプラガブルに選択できるストリーム処理基盤となっており、必要なタスクを組み合わせることでデータの転送と前処理を実現することができます。
機械学習を支えるアノテーションシステム
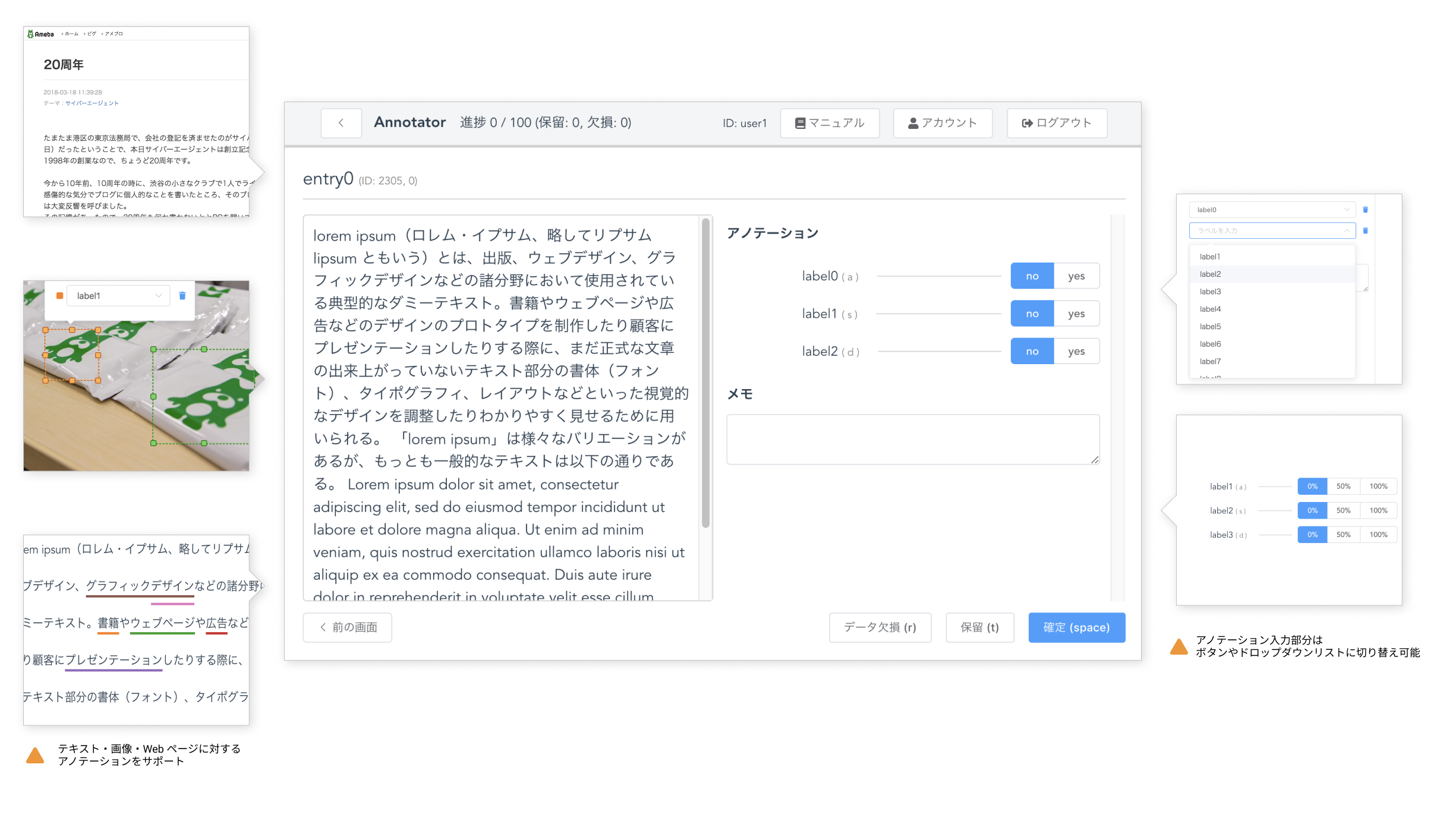
機械学習で高い精度を達成するためには豊富で正確な学習データが重要です。コンテンツ推薦などでは閲覧履歴のようなユーザのフィードバックを学習データとして用いることができますが、スパム検知のように学習データを人手で作成しなければならない課題も多くあります。そこで、Media Data Tech Studioでは学習データの作成(アノテーション)を支援するための汎用的なシステム Orion Annotator を開発しています。Orion Annotator はアノテーションを行うアノテータと、アノテーションデータを利用するエンジニアの双方について、アノテーションに本質的でない作業を自動化・効率化するシステムです。
まず、Orion Annotator はアノテータが効率的に作業するためのインターフェースを提供します。煩雑な操作を軽減しストレスなくアノテーションできる環境を実現することで、高品質なデータをより多く作成できます。また、インターフェースは高いカスタマイズ性を備えており、様々な課題に対して最適なものを設定できます。
次に、Orion Annotator はエンジニアがアノテーションデータを容易に扱うためのデータフローを提供します。データフローは当社の DWH である Patriot やバッチ処理システムと連携することで、アノテーション対象データのインポートやアノテーション結果の出力を自動化し、データの分析や活用を促進しています。
まず、Orion Annotator はアノテータが効率的に作業するためのインターフェースを提供します。煩雑な操作を軽減しストレスなくアノテーションできる環境を実現することで、高品質なデータをより多く作成できます。また、インターフェースは高いカスタマイズ性を備えており、様々な課題に対して最適なものを設定できます。
次に、Orion Annotator はエンジニアがアノテーションデータを容易に扱うためのデータフローを提供します。データフローは当社の DWH である Patriot やバッチ処理システムと連携することで、アノテーション対象データのインポートやアノテーション結果の出力を自動化し、データの分析や活用を促進しています。