プレスリリース
AI Lab、情報検索・推薦システム分野のトップカンファレンス「SIGIR」にて共著論文採択 ー大規模推薦システムのための高精度なランキング学習を可能にする手法を提案ー

株式会社サイバーエージェント(本社:東京都渋谷区、代表取締役:藤田晋、東証一部上場:証券コード4751)は、人工知能技術の研究開発組織「AI Lab」に所属する研究員の富樫陸・加藤真大・大谷まゆ、ならびに情報検索評価における第一人者の早稲田大学酒井哲也教授、画像・映像検索研究における第一人者でありアドバイザーの佐藤真一教授らによる共著論文が、情報検索分野の国際会議「The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2021)」※1 にて採択されたことをお知らせいたします。
「SIGIR」は世界中の研究者によって毎年開催される国際会議で、情報検索・推薦システムの分野でもっとも権威ある国際会議の一つです。この度「AI Lab」から採択された論文は、2021年7月にオンラインで開催される「SIGIR 2021」で発表されます。
■研究背景
「AI Lab」ではマーケティング全般に関わる幅広いAI技術を研究・開発しており、大学・学術機関との産学連携を強化しながら様々な技術課題に取組んでいます。
近年、インターネット広告を含め様々なウェブサービスにおいて、ユーザー毎に好まれる配信コンテンツや広告を高精度に予測する技術は、ユーザーの満足度を左右する重要な役割を果たしています。
しかし、インターネットの普及に伴うユーザーや配信コンテンツの急激な増加により、効果予測システムの学習・予測にかかる膨大なコストが課題となっています。
このような課題から、大量のユーザー・配信コンテンツに対する効果予測の技術的課題解決を行う領域が注目を集めており、当社ではこれまで佐藤真一氏との産学連携のもと、推薦システムに関する共著論文を「WSDM 2021」 「WWW 2021」で発表するなど、積極的に共同研究に取組んでまいりました。
■論文の概要
今回採択された共著論文「Scalable Personalised Item Ranking through Parametric Density Estimation」※2 では、大規模推薦システムのための密度推定に基づくランキング学習手法を開発し提案しました。
・ランキング学習とサンプリング学習について
一般的に、様々なサービスにおける推薦システムの開発では「ランキング学習(Learning to rank)」という機械学習技術が広く用いられており、その学習を補助する手法として「サンプリング学習」が活用されています。
「ランキング学習」では推薦モデルを学習し推薦精度の向上を行い、「サンプリング学習」ではサンプラーモデルを学習し、大規模な学習データの中から適切なサンプルを選択することで推薦モデルの効果的・効率的な学習を行います。
このように、ランキング学習とサンプリング学習を組み合わせることで、推薦システムの学習効率化と性能向上が期待できますが、最新のGenerative Adversarial Network (GAN)や強化学習を用いたサンプリング学習は、推薦モデルに加えて複雑なサンプラーモデルの訓練を必要とするため、計算コストが高く実応用が難しいという課題がありました。
・提案手法
本研究では、クリックや購買などの履歴データを活用した密度推定に基づく目的関数と新たな正則化手法を提案しています。
今回新たに提案した学習手法では、最適なサンプラーモデルが学習中の推薦モデルと一致するため、追加のサンプラーモデルを必要とせず、推薦モデル単体での学習を可能にしています。結果として、推薦モデルの精度を損なうことなく、サンプラーモデルによる計算コストを削減することを実現しました。
▼提案手法の性能イメージ
「SIGIR」は世界中の研究者によって毎年開催される国際会議で、情報検索・推薦システムの分野でもっとも権威ある国際会議の一つです。この度「AI Lab」から採択された論文は、2021年7月にオンラインで開催される「SIGIR 2021」で発表されます。
■研究背景
「AI Lab」ではマーケティング全般に関わる幅広いAI技術を研究・開発しており、大学・学術機関との産学連携を強化しながら様々な技術課題に取組んでいます。
近年、インターネット広告を含め様々なウェブサービスにおいて、ユーザー毎に好まれる配信コンテンツや広告を高精度に予測する技術は、ユーザーの満足度を左右する重要な役割を果たしています。
しかし、インターネットの普及に伴うユーザーや配信コンテンツの急激な増加により、効果予測システムの学習・予測にかかる膨大なコストが課題となっています。
このような課題から、大量のユーザー・配信コンテンツに対する効果予測の技術的課題解決を行う領域が注目を集めており、当社ではこれまで佐藤真一氏との産学連携のもと、推薦システムに関する共著論文を「WSDM 2021」 「WWW 2021」で発表するなど、積極的に共同研究に取組んでまいりました。
■論文の概要
今回採択された共著論文「Scalable Personalised Item Ranking through Parametric Density Estimation」※2 では、大規模推薦システムのための密度推定に基づくランキング学習手法を開発し提案しました。
・ランキング学習とサンプリング学習について
一般的に、様々なサービスにおける推薦システムの開発では「ランキング学習(Learning to rank)」という機械学習技術が広く用いられており、その学習を補助する手法として「サンプリング学習」が活用されています。
「ランキング学習」では推薦モデルを学習し推薦精度の向上を行い、「サンプリング学習」ではサンプラーモデルを学習し、大規模な学習データの中から適切なサンプルを選択することで推薦モデルの効果的・効率的な学習を行います。
このように、ランキング学習とサンプリング学習を組み合わせることで、推薦システムの学習効率化と性能向上が期待できますが、最新のGenerative Adversarial Network (GAN)や強化学習を用いたサンプリング学習は、推薦モデルに加えて複雑なサンプラーモデルの訓練を必要とするため、計算コストが高く実応用が難しいという課題がありました。
・提案手法
本研究では、クリックや購買などの履歴データを活用した密度推定に基づく目的関数と新たな正則化手法を提案しています。
今回新たに提案した学習手法では、最適なサンプラーモデルが学習中の推薦モデルと一致するため、追加のサンプラーモデルを必要とせず、推薦モデル単体での学習を可能にしています。結果として、推薦モデルの精度を損なうことなく、サンプラーモデルによる計算コストを削減することを実現しました。
▼提案手法の性能イメージ
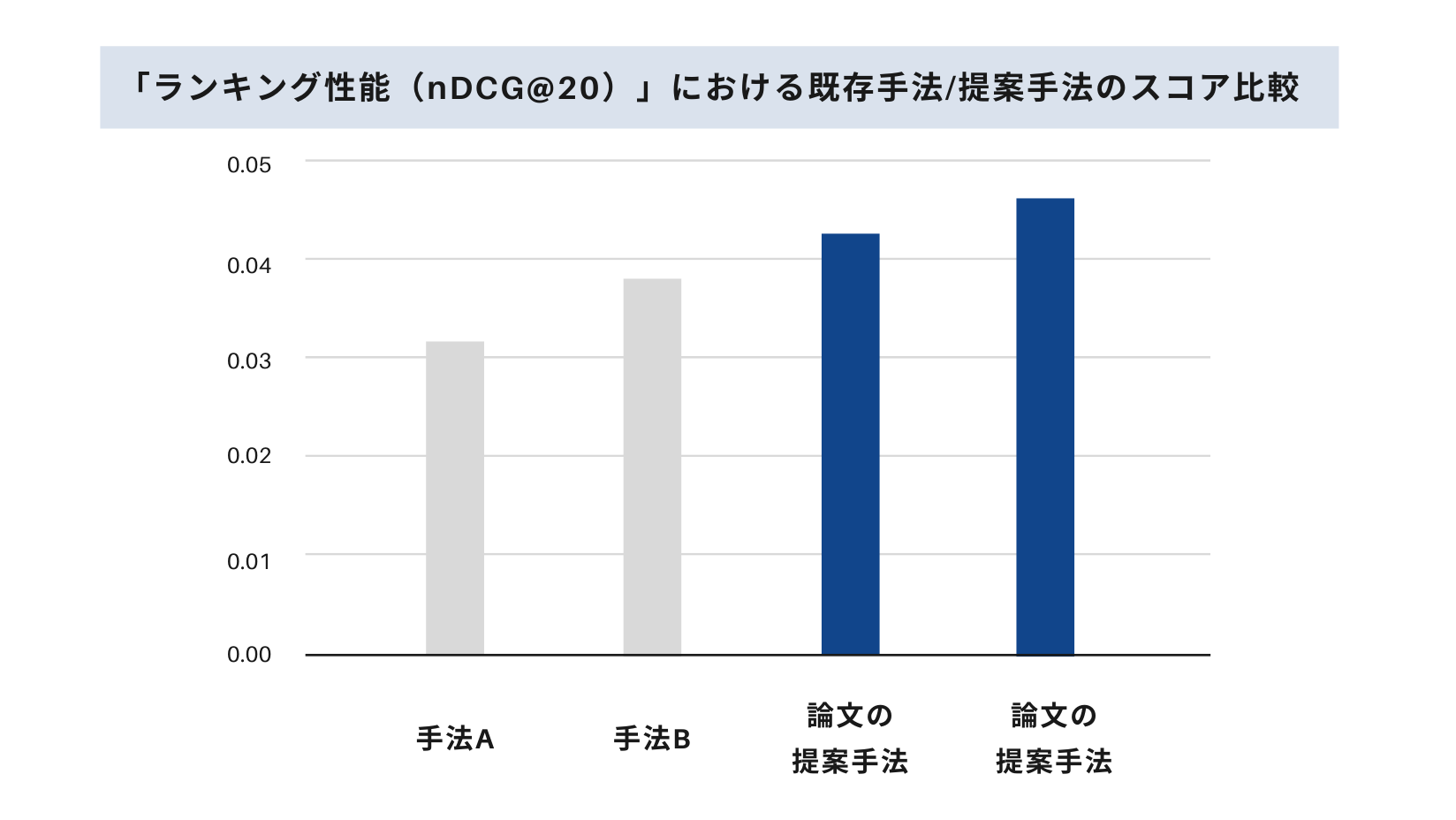
さらに、ある条件下で、本提案手法がGANを元にしたサンプリング手法IRGAN ※3 と一致することを示すことで、高コストで実応用が難しいIRGANのようなサンプラーモデルを省略できる可能性も示唆しています。
また、論文では本提案手法と、一般的なランキング学習の1つである「ペアワイズ学習」※4との関連性についても議論しており、今回の提案手法とペアワイズ学習の性能差を埋める正則化手法も提案しています。
本提案手法は、大規模データを用いた学習に必須である「オンライン学習」に対応しており、提案した正則化手法は、Graph Neural Networkの一部にも適用可能なことを確認しています。
■今後
今回の提案手法は、学習に時間や計算コストがかかる複雑な深層モデルを推薦システムに導入するための基盤技術となるとともに、大量の広告クリエイティブの効果予測時における、精度および効率の向上に繋がることが期待されます。「AI Lab」は今後も、AI技術を取り入れた、より品質の高い広告配信技術の実現を目指し、研究・開発に努めてまいります。
※1 「The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval」
※2 Riku Togashi, Masahiro Kato, Mayu Otani, Tetsuya Sakai, Shin'ichi Satoh. "Scalable Personalised Item Ranking through Parametric Density Estimation"
※3 Jun Wang, Lantao Yu, Weinan Zhang, Yu Gong, Yinghui Xu, Benyou Wang, Peng Zhang and Dell Zhang, IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models
※4 ペアワイズ学習:ランキング学習で一般的に用いられる手法の1つ
また、論文では本提案手法と、一般的なランキング学習の1つである「ペアワイズ学習」※4との関連性についても議論しており、今回の提案手法とペアワイズ学習の性能差を埋める正則化手法も提案しています。
本提案手法は、大規模データを用いた学習に必須である「オンライン学習」に対応しており、提案した正則化手法は、Graph Neural Networkの一部にも適用可能なことを確認しています。
■今後
今回の提案手法は、学習に時間や計算コストがかかる複雑な深層モデルを推薦システムに導入するための基盤技術となるとともに、大量の広告クリエイティブの効果予測時における、精度および効率の向上に繋がることが期待されます。「AI Lab」は今後も、AI技術を取り入れた、より品質の高い広告配信技術の実現を目指し、研究・開発に努めてまいります。
※1 「The 44th International ACM SIGIR Conference on Research and Development in Information Retrieval」
※2 Riku Togashi, Masahiro Kato, Mayu Otani, Tetsuya Sakai, Shin'ichi Satoh. "Scalable Personalised Item Ranking through Parametric Density Estimation"
※3 Jun Wang, Lantao Yu, Weinan Zhang, Yu Gong, Yinghui Xu, Benyou Wang, Peng Zhang and Dell Zhang, IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models
※4 ペアワイズ学習:ランキング学習で一般的に用いられる手法の1つ