プレスリリース
AI Lab、自然言語処理分野のトップカンファレンス「EMNLP 2024」にて論文採択
―人間のフィードバックに基づく強化学習(RLHF)における高品質な学習データ選定手法を提案―

株式会社サイバーエージェント(本社:東京都渋谷区、代表取締役:藤田晋、東証プライム市場:証券コード4751)は、人工知能技術の研究開発組織「AI Lab」に所属する研究員の森村哲郎・坂本充生・陣内佑・阿部拳之・蟻生開人による論文が、人工知能分野および自然言語処理分野の国際会議「EMNLP 2024(The 2024 Conference on Empirical Methods in Natural Language Processing、以下EMNLP)」※1に採択されたことをお知らせいたします。なお当社において、「EMNLP」本会議での採択は初となります。
「EMNLP」は世界中の研究者によって定期開催される国際会議で、「ACL」「NAACL」※2と並び、自然言語処理分野(NLP)でもっとも権威ある国際会議のひとつです。このたび採択された論文は、2024年11月にアメリカ・フロリダ州のマイアミで開催される「EMNLP 2024」での発表を予定しています。
「EMNLP」は世界中の研究者によって定期開催される国際会議で、「ACL」「NAACL」※2と並び、自然言語処理分野(NLP)でもっとも権威ある国際会議のひとつです。このたび採択された論文は、2024年11月にアメリカ・フロリダ州のマイアミで開催される「EMNLP 2024」での発表を予定しています。
■背景
近年、AI技術の中核を担う大規模言語モデル(LLM)の開発が世界的に加速しています。日本においてもLLMのビジネス応用の重要性が高まっており、広告やマーケティング分野でもその活用方法が注目されています。
広告効果の向上には、ユーザー一人ひとりの嗜好や興味に合わせ最適なメッセージを届けることが不可欠です。LLMを活用することで、人間の価値観や意図に沿った適切な応答生成が可能となり、効率化と品質向上が期待されています。
このような背景のもと、AI LabのReinforcement Learning(強化学習)チーム では自然言語処理分野の研究チームとも連携しLLMを活用した高品質なテキストの自動生成など、広告効果向上に向けた研究開発に取り組んでまいりました。
本研究では特に、RLHF(人間のフィードバックに基づく強化学習)を用いたLLMの「アライメント」技術に焦点を当てています。本技術により、LLMの応答をよりユーザーに適したものに調整し、広告やマーケティングの効果を最大化することを目指しています。
広告効果の向上には、ユーザー一人ひとりの嗜好や興味に合わせ最適なメッセージを届けることが不可欠です。LLMを活用することで、人間の価値観や意図に沿った適切な応答生成が可能となり、効率化と品質向上が期待されています。
このような背景のもと、AI LabのReinforcement Learning(強化学習)チーム では自然言語処理分野の研究チームとも連携しLLMを活用した高品質なテキストの自動生成など、広告効果向上に向けた研究開発に取り組んでまいりました。
本研究では特に、RLHF(人間のフィードバックに基づく強化学習)を用いたLLMの「アライメント」技術に焦点を当てています。本技術により、LLMの応答をよりユーザーに適したものに調整し、広告やマーケティングの効果を最大化することを目指しています。
■論文の概要
今回採択された論文「Filtered Direct Preference Optimization」では、LLMを人間のフィードバックに基づいてアライメントする手法として注目されているDPO(Direct Preference Optimization)に対する新しいアプローチ「Filtered DPO」を提案しています。DPOは、従来の強化学習手法を用いたアプローチと異なり、人間によるフィードバックを学習データとして直接LLMの応答を最適化する手法です。
本研究ではまず、学習データに質の低い応答が混在している場合、DPOの性能が大きく劣化することを明らかにしました。次に、この問題に対処するため、データの品質に基づいて不要なデータを取り除く手法を導入しました(図1参照)。
実験の結果、提案法である「Filtered DPO」は従来のDPOと比較して、データの品質がまばらな場合でもより安定した高品質な応答を生成できることが確認されました(図2参照)。
本研究ではまず、学習データに質の低い応答が混在している場合、DPOの性能が大きく劣化することを明らかにしました。次に、この問題に対処するため、データの品質に基づいて不要なデータを取り除く手法を導入しました(図1参照)。
実験の結果、提案法である「Filtered DPO」は従来のDPOと比較して、データの品質がまばらな場合でもより安定した高品質な応答を生成できることが確認されました(図2参照)。
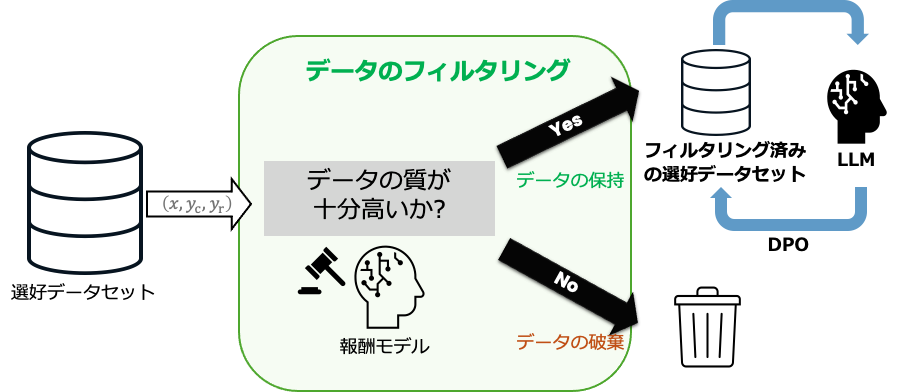
報酬モデルを用いてデータの品質を評価し、LLMが生成する応答よりも低品質な場合はデータを除去します。このフィルタリングによって、質の高いデータのみを用いた学習が可能になります。
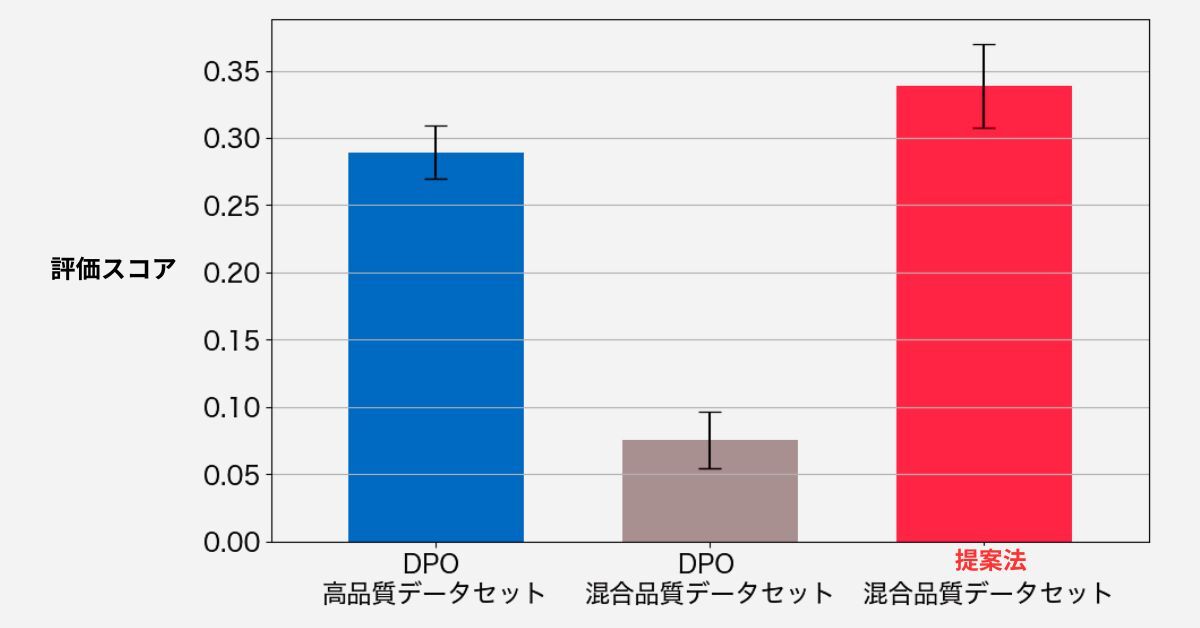
高品質データセットと混合品質データセットでの性能を比較しており、提案法は混合品質データセットにおいても高い評価スコアを示しました。
■今後
LLMのアライメント技術は、広告生成、対話応答、シナリオ作成など多岐にわたる分野で重要性を増しています。その精度は学習データの品質に大きく依存しますが、データ量の増加に伴い低品質なデータの混入は避けられません。本研究の提案法である「Filtered DPO」は、こうしたデータを効果的にフィルタリングし、LLMの性能を安定的に向上させることを可能にします。
本研究の成果は、広告テキストの制作に加えて、当社で取り組む極予測シリーズにおける「広告テキストの自動生成技術」や審査AIでの「広告クリエイティブの自動審査」への活用等が期待されます。今後も「AI Lab」では、最先端のAI技術研究に取り組み、より使いやすく高性能なLLMの開発を進めるとともに、強化学習の実用化と進展に貢献してまいります。
※1 「EMNLP」The 2024 Conference on Empirical Methods in Natural Language Processing
※2 「ACL」Annual Meeting of the Association for Computational Linguistics
「NAACL」Annual Conference of the North American Chapter of the Association for Computational Linguistics
本研究の成果は、広告テキストの制作に加えて、当社で取り組む極予測シリーズにおける「広告テキストの自動生成技術」や審査AIでの「広告クリエイティブの自動審査」への活用等が期待されます。今後も「AI Lab」では、最先端のAI技術研究に取り組み、より使いやすく高性能なLLMの開発を進めるとともに、強化学習の実用化と進展に貢献してまいります。
※1 「EMNLP」The 2024 Conference on Empirical Methods in Natural Language Processing
※2 「ACL」Annual Meeting of the Association for Computational Linguistics
「NAACL」Annual Conference of the North American Chapter of the Association for Computational Linguistics