プレスリリース
AI Lab、コンピュータビジョン分野のトップカンファレンス「ICCV」にて主著論文採択 グラフィックデザイン自動生成手法を提案 - ICCVにて2本の論文採択へ -

株式会社サイバーエージェント(本社:東京都渋谷区、代表取締役社長:藤田晋、東証一部上場:証券コード4751)は、人工知能技術の研究開発組織「AI Lab」に所属するリサーチサイエンティストの山口光太による論文が、コンピュータビジョン分野の国際会議「ICCV 2021」※1にて採択されたことをお知らせいたします。
「ICCV」は隔年開催されるコンピュータビジョン・画像認識分野の国際会議で、「CVPR」※2「ECCV」※3などと並び、分野で権威のある学会の一つです。2021年度は採択率がおよそ25%でした。この度「AI Lab」からは本件並びに、AI Labリサーチサイエンティストの下田和、山口光太、九州大学大学院の原口大地氏、内田誠一教授による共著論文※4の2本が採択されており、2021年10月にオンラインで開催される「ICCV 2021」で発表を行います。
※4 共著論文「De-rendering Stylized Texts」についてはこちらのプレスリリースで詳細をご確認ください
■研究背景
「AI Lab」のCreative Research Teamではクリエイティブ表現全般に関わる幅広いAI技術を研究し、効果を出す広告クリエイティブの制作に重要なクリエイティブデザインの制作支援や自動化に関するAI技術の研究開発に取り組んでいます。本研究では、クリエイティブ制作で重要な「ベクタ形式」の画像生成について手法を提案いたしました。
バナー広告や動画広告をはじめとするクリエイティブデザインを制作する際、ベクタ形式と呼ばれる、構成する図形やテキストの集まりとして画像を記録するフォーマット(拡張子:AIやPDF)で制作編集をすることが一般的です。ラスタ形式と呼ばれる、デザインが1ピクセル単位のドットで構成されたフォーマット(拡張子:JPEGやPNG)とは異なり、ベクタ形式では物体やテキストとその装飾に関するメタデータの集合として、生データで情報を保存します。こうすることで、拡大や変容にも強く容易にテキストの色を変更したり、物体の配置を細かく調整することができるようになります。
これに対し、ここ数年話題となってきた敵対的生成ネットワーク(GAN)のような画像生成技術では、直接ピクセルを出力する、ラスタ形式の手法が一般的でした。しかし、一度生成されたラスタ形式のピクセル画像を人が再編集することは難しく、またGANによる生成画像の品質を完全に制御することも困難でした。このため、細かいデザインの調整を前提とする広告クリエイティブ制作では、ピクセル画像で生成するGANなど、既存の画像生成技術を直接導入することが難しいという課題がこれまでありました。
■論文研究の概要
このような背景のもと、当社ではベクタ形式の画像オブジェクトを直接生成する深層学習モデルの構築に取り組み、研究を進めてまいりました。今回ICCVに採択された論文「CanvasVAE: Learning to Generate Vector Graphic Documents」※5では、Variational Auto-Encoder(VAE)と呼ばれるニューラルネットワークを使い、ベクタ形式の画像オブジェクトを再構築・生成する学習手法を開発し、提案しました。
これまで、GAN・VAEともにラスタ形式の画像を生成する深層学習モデルは存在しましたが、本提案のようにベクタ形式の画像を直接扱い、完全にベクタ形式で生成されるモデルはありませんでした。
本研究では、ベクタ形式の画像オブジェクトを、全体を表す「キャンバス」と、テキストやあしらいなどの「個別要素」の集合から位置付け、代表的なニューラルネットワークの構造の一つであるVAEモデル構造とTransformer構造を組み合わせて情報表現する方法で、学習する手法を提案しています。
「ICCV」は隔年開催されるコンピュータビジョン・画像認識分野の国際会議で、「CVPR」※2「ECCV」※3などと並び、分野で権威のある学会の一つです。2021年度は採択率がおよそ25%でした。この度「AI Lab」からは本件並びに、AI Labリサーチサイエンティストの下田和、山口光太、九州大学大学院の原口大地氏、内田誠一教授による共著論文※4の2本が採択されており、2021年10月にオンラインで開催される「ICCV 2021」で発表を行います。
※4 共著論文「De-rendering Stylized Texts」についてはこちらのプレスリリースで詳細をご確認ください
■研究背景
「AI Lab」のCreative Research Teamではクリエイティブ表現全般に関わる幅広いAI技術を研究し、効果を出す広告クリエイティブの制作に重要なクリエイティブデザインの制作支援や自動化に関するAI技術の研究開発に取り組んでいます。本研究では、クリエイティブ制作で重要な「ベクタ形式」の画像生成について手法を提案いたしました。
バナー広告や動画広告をはじめとするクリエイティブデザインを制作する際、ベクタ形式と呼ばれる、構成する図形やテキストの集まりとして画像を記録するフォーマット(拡張子:AIやPDF)で制作編集をすることが一般的です。ラスタ形式と呼ばれる、デザインが1ピクセル単位のドットで構成されたフォーマット(拡張子:JPEGやPNG)とは異なり、ベクタ形式では物体やテキストとその装飾に関するメタデータの集合として、生データで情報を保存します。こうすることで、拡大や変容にも強く容易にテキストの色を変更したり、物体の配置を細かく調整することができるようになります。
これに対し、ここ数年話題となってきた敵対的生成ネットワーク(GAN)のような画像生成技術では、直接ピクセルを出力する、ラスタ形式の手法が一般的でした。しかし、一度生成されたラスタ形式のピクセル画像を人が再編集することは難しく、またGANによる生成画像の品質を完全に制御することも困難でした。このため、細かいデザインの調整を前提とする広告クリエイティブ制作では、ピクセル画像で生成するGANなど、既存の画像生成技術を直接導入することが難しいという課題がこれまでありました。
■論文研究の概要
このような背景のもと、当社ではベクタ形式の画像オブジェクトを直接生成する深層学習モデルの構築に取り組み、研究を進めてまいりました。今回ICCVに採択された論文「CanvasVAE: Learning to Generate Vector Graphic Documents」※5では、Variational Auto-Encoder(VAE)と呼ばれるニューラルネットワークを使い、ベクタ形式の画像オブジェクトを再構築・生成する学習手法を開発し、提案しました。
これまで、GAN・VAEともにラスタ形式の画像を生成する深層学習モデルは存在しましたが、本提案のようにベクタ形式の画像を直接扱い、完全にベクタ形式で生成されるモデルはありませんでした。
本研究では、ベクタ形式の画像オブジェクトを、全体を表す「キャンバス」と、テキストやあしらいなどの「個別要素」の集合から位置付け、代表的なニューラルネットワークの構造の一つであるVAEモデル構造とTransformer構造を組み合わせて情報表現する方法で、学習する手法を提案しています。
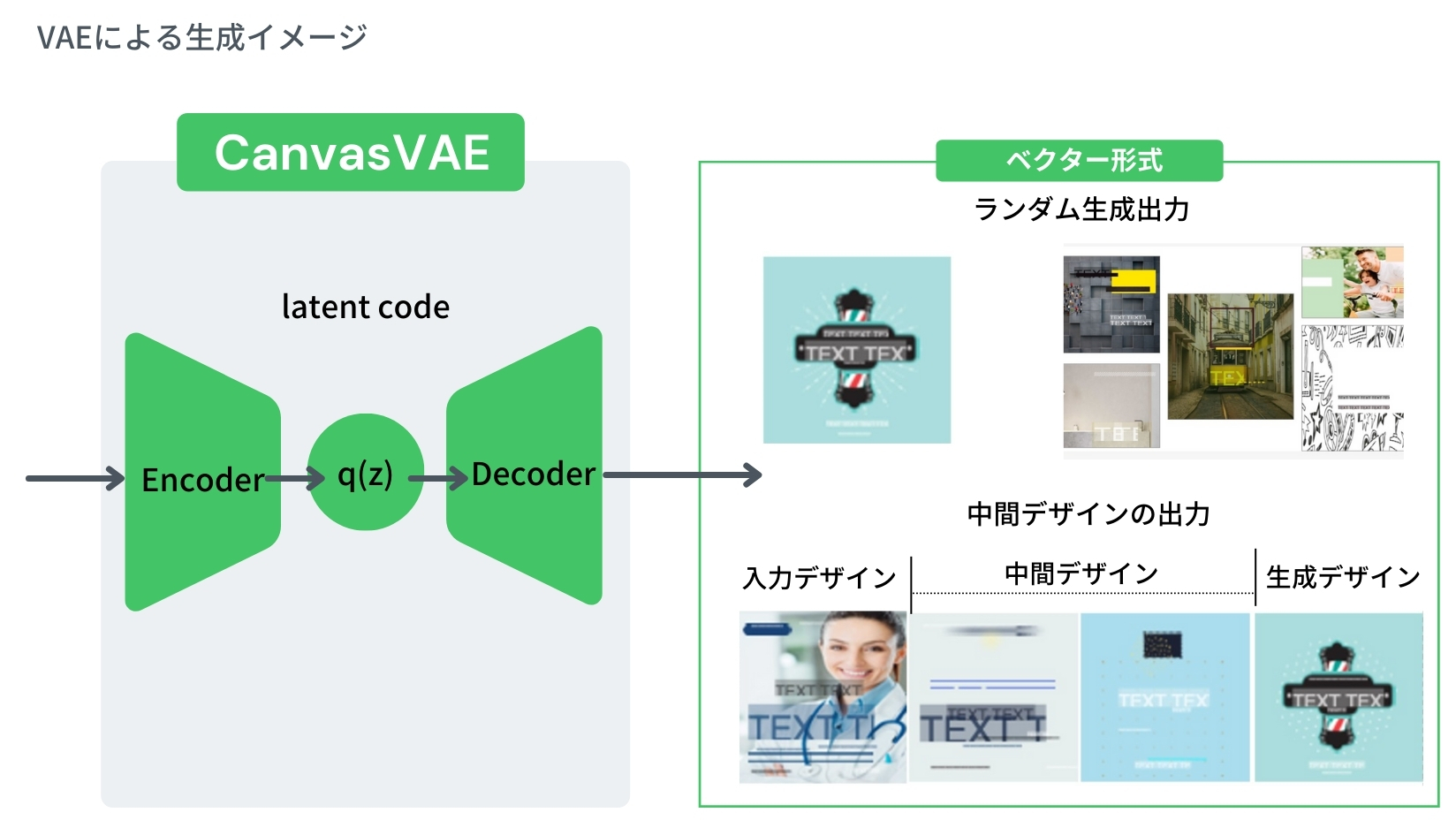
また、VAEによってランダムにベクタ形式の画像オブジェクトを新しく生成するだけでなく、既存の再構成出力デザインとの中間デザインを生成することも可能となります。
本手法を用いて自動生成された画像はベクタ形式のため、人が容易に再編集を加えることが可能です。このため、多数の画像を自動生成し、デザイナーが良質なデザインを選んで編集するといった制作スタイルも可能となります。
■今後
今回の提案手法は、バナー広告のようなグラフィックデザインの自動生成への応用が期待されます。また、当社が提供する「極予測AI」と組み合わせることで、広告効果の高い「編集可能な」クリエイティブを自動的に生成することも可能となります。「AI Lab」は今後もAI技術を用いたクリエイティブ制作、自動生成技術をプロダクトに導入すべく、果敢に研究開発に努めてまいります。
出典
※1 「International Conference on Computer Vision」
※2 「Conference on Computer Vision and Pattern Recognition」
※3 「European Conference on Computer Vision」
※4 共著論文「De-rendering Stylized Texts」についてはこちらのプレスリリースで詳細をご確認ください
※5 Kota Yamaguchi, CanvasVAE: Learning to Generate Vector Graphic Documents, ICCV 2021