日本の生成AIの発展まで目指す
サイバーエージェントがLLM開発に踏み込む理由

2023年5月、サイバーエージェントは130億パラメータの独自の日本語LLM(大規模言語モデル)を開発したことを発表、さらにその翌週には最大68億パラメータの商用利用可能な日本語LLMを一般公開した。
原子力やコンピューター登場と同等のインパクトがあると多くの研究者が語る「生成AI」の登場。生成AIの中でもテキストに特化した「LLM」は、その技術を応用した代表的なサービス「ChatGPT」を筆頭に、世界中で注目を浴びている。
時計の針を巻き戻すこと約1年半。現在のブームが起こるその前に、サイバーエージェントは着実に独自のLLM開発をスタートしていた。
当時なぜLLMを開発をすることになり、今回一般公開を行ったのか、またこの先目指す世界について開発の発起人である石上・開発責任者の玉津・ビジネス責任者の毛利に語ってもらった。
Profile
-

石上 亮介
株式会社サイバーエージェント
AI事業本部 AIクリエイティブDiv 機械学習エンジニア
2021年 株式会社サイバーエージェント 中途入社。前職はAIベンチャーにてデータ分析業務に従事。現在はAI事業本部で「極予測LP」の開発、大規模言語モデル(LLM)をはじめとした基盤モデルプロジェクトのリードを担当。画像やテキストを対象としたマルチモーダルなAIの社会実装に従事している。 -

玉津 宗太郎
株式会社サイバーエージェント
AI事業本部 AIクリエイティブDiv ソフトウェアエンジニア
2018年 サイバーエージェント新卒入社。アドテク事業部にて新規事業立ち上げに従事した後、AI事業本部で「極予測LP」のエンジニアリングマネジメント、プロダクトマネジメントを担当。大規模言語モデル(LLM)をはじめとした基盤モデルの事業応用に従事している。IPA未踏スーパークリエイター認定。 -

毛利 真崇
株式会社サイバーエージェント
AI事業本部 AIクリエイティブDiv 統括
2005年サイバーエージェント新卒入社。 広告代理事業の営業に従事した後、セントラルアカウントデザイン室を立ち上げ、広告プロダクトのアルゴリズム解析および運用設計、自動化ツールのプロダクトマネージャーを担当。2017年にAIクリエイティブDivを立ち上げ、AIや3DCGを活用した広告クリエイティブの効果予測や自動生成の研究開発のビジネス開発責任者・統括として従事。
なぜCAがLLM? 1年半前にスタートした開発背景
ーLLM開発は今から1年半前と、かなり早いタイミングでスタートしたと聞きました。当時なぜ開発を始めたのでしょうか
毛利:サイバーエージェントでは、2017年からAIクリエイティブの部署を立ち上げ、AIを活用した効果の高い広告クリエイティブ制作に取り組んできました。実際にこれまで、効果予測AIで広告効果を最大化する「極予測AI」や検索連動型広告の効果を改善する「極予測TD」、さらにランディングページを予測・制作し運用する「極予測LP」など多くのサービスを提供しています。 今回LLM開発の発起人となった機械学習エンジニアの石上と極予測LP開発責任者の玉津は、このAIクリエイティブ領域のサービス開発に携わっていたメンバーです。
石上: 極予測シリーズで用いられているAI技術の1つに、効果の高い広告のキャッチコピーを自動生成するAIがありますが、この精度向上に当時話題になっていたLLMが活きると考えました。LLMに関してモデルの大きさと学習データ量を増やすことで性能が上がることが分かってきており※、その方針で開発がスタートしました。
※OpenAIがに公開した論文『Scaling Laws for Neural Language Models』2020年1月 公開

ー 広告事業の延長線上でLLM開発がスタートしたのですね。LLMにより、具体的に何が可能になるのでしょうか
毛利:広告という点に絞っていうと、AIがより人間に近いコピーライティングができるようになります。LLMは簡単に表現すると、「大規模なテキストを読み込ませたスゴイ脳」を開発した、と言うとイメージしやすいかもしれません。
これまでのAIの活用方法では作りたいものに対して、関連するデータをその都度収集し、学習させていました。しかし、LLMでは事前にあらゆる情報を学習させておきます。この事前学習を済ませたLLM(脳)は汎用性が高く、僅かな学習でより高品質な結果を出力できるようになります。
玉津:その「脳」に対し、対話データ等を用いて追加で学習を行うと「ChatGPT」のような高性能なチャットボットが出来上がる、というようなイメージです。
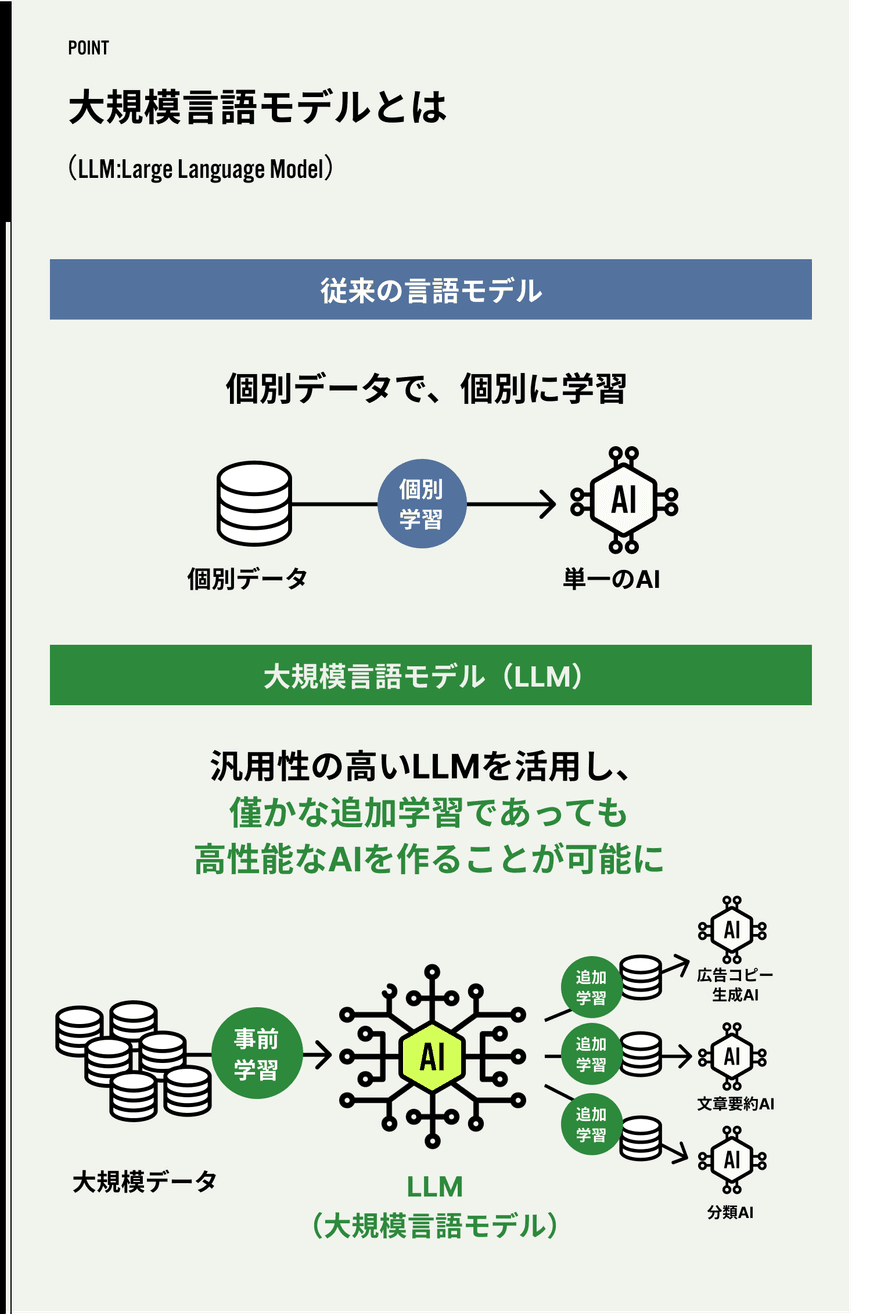
ーあくまで今回公開したのは「脳」となる基盤であって、ChatGPTのようなチャット ボットサービスではない、と。
玉津:よく間違われることが多いのですが、その通りです。
私たちはChatGPTのベースとなっている基盤モデル部分 (事前学習のみ行ったもの) に該当するものを自社で開発し公開した、という位置付けになるので、ChatGPTと比較できるものではないのですし 、そもそもChatGPTに勝とうとしてこの開発を始めたわけではありません
ーではなぜ、今回独自でLLMを開発したのでしょうか。GPT-3、GPT-4をはじめとする既存のLLMを活用するのも一手では?
石上:これが今回、自社でLLMを開発する決断を下した最大の理由ですが、既存のものはLLM自体のカスタマイズができないという問題が存在していました。
私たちはあくまで精度の高い広告キャッチコピーを作りたかったので、例えば、媒体やターゲットごとに合わせた自然な日本語でテキストを生成したい。
しかし、GPT-3・GPT-4といったLLMはそもそも学習データが英語中心であったり、チューニング自体ができないモデルもあったりと、出来ることに制限がありました。
そこで、自分たちでLLMを開発し、汎用的なものはGPT-3やGPT-4を使いつつ、より独自性がより求められる部分は日本語データを学ばせた自社LLMを使うなど、使い分けをしていこうとなったのです。
さらに自社でLLM開発をしておけば、効果予測データをもとに効果の高い広告をフィードバックし、LLMを学習させていくこともできます。
こうして、学習期間約1年半をかけ日本語に強いLLMが出来上がりました。
鍵はスピード感。全て自社完結のLLM開発
ーLLM開発をすること自体、とても難易度が高いように思えますが、必要な開発アセットは何でしたか
石上:大量のデータを扱うLLM開発ができるエンジニアや研究者が必要なのはもちろんのこと、計算リソース(GPUと呼ばれるマシンが一般的)の確保も大事でした。
開発を行なっていたのは、私や玉津などAIクリエイティブ領域に所属するエンジニア数名が中心となっていましたが、研究開発組織「AI Lab」のNLPチームと日本語データに関する連携も行なっていました。
さらにモデルに学習をさせるための計算リソースの準備も必須。LLMを開発する上で、この計算リソースが多ければ多いほどより早く学習が終わります。
日本に最先端GPU自体を仕入れること自体のハードルが高い中で、NVIDIAと業務提携をしていることで最新のGPUであるNVIDIA H100を導入することができたのも大きかったです。ここは社内の専門インフラ組織「CIU」と密な連携をとりながら実現をしました。

ー多角的な技術力・技術投資がないと実現できなかったプロジェクトだったのですね
玉津:そうですね。LLMの学習には大きな費用が必要となるため、事業として見た場合、効率的に高品質なモデルを開発するノウハウの蓄積も重要です。サイバーエージェントは、全ての開発を社内で完結しているのでノウハウが蓄積できますし、かつ少数精鋭で意思決定しながらスピーディーに進められる強さがあります。
とにかく流れの早い生成AI領域において開発を進めるのは、経営陣の技術理解があり、技術領域の垣根を越えて連携が取れる体制と文化がなかったら成し得なかったことだと思います。
日本のAI技術に貢献したい。モデル公開に踏み切った意図
ー今年5月、130億パラメータのLLM開発を発表。さらにその翌週には68億パラメータのモデル自体を公開しました。多くの反響がありましたが、なぜモデルを公開したのでしょうか?
石上:正直、予想以上に反響がありました。
この2つのモデルの違いは学ばせている学習データが異なっており、オープンにした68億のモデルは、wikipedia・コモンクロールなど全て透明性のあるデータをもとにモデルを作っています。
※130億はパラメータのモデルには、一部自社データが含まれる
モデルの公開については、LLM開発の構想を考えた時からすでに視野に入れており、実は最初からオープンなものを作りたいと思っていました。
というのも、そもそも日本語に強いLLMというものが日本全体で少なく、そこに課題を感じていたのです。海外はフェアユース※という文化があり技術発展への理解が深いため使えるデータも多い印象ですが、日本ではまだそこが弱い。学習できるオープンな日本語文章のデータが少なかったり、計算リソースも限られている。
※一定の条件を満たしていれば、著作権者から許可を得なくても、著作物を再利用できることを示した法原理
となると、いつまで経っても海外製のAIに遅れをとってしまう。
これを本気でやっていくには、1社だけでは無理で、国や企業・アカデミアと連携してLLMを作る必要があるのです。自分たちだけで技術を独占するのではなく、オープンなものを作って多くの人を巻き込んで性能を上げていき、日本の技術競争力に貢献する必要があると考えています。
そこで今回、一般公開を行いました。
ー実際に、商用利用可能なLLMは小さなサイズのモデルも含め6種類公開されました
玉津:ビジネスとして見た時に、モデルサイズは大きければ大きいほど良い、というものではありません。モデルサイズ以外の条件が同じ場合、大きければ生成品質は高くなる可能性は高いですが、モデルの運用コストもより必要になってくるのでそのバランスが必要で、応用場面に応じて使い分けが必要になってきます。
今回公開したモデルは、アカデミアなどの研究室はもちろん、個人の研究者/開発者が自身のPC等でも動かせるように複数のサイズのモデルを公開しました。多くの人が触れることで、裾野を広げることが大事だと思ったからです。
引き続き性能向上を目指している最中ですが、日本語の性能が100%完璧でないタイミングで公開することで、ここは良い・ここはまだだね、という皆さんのフィードバックをもとに日本全体でモデルを作っていきたいと考えています。

サイバーエージェントの企業競争力の源泉へ
ー今後も期待されるLLM開発ですが、どのようなことを視野に入れていますか?
石上:研究開発という点では、より性能が良いモデル開発を目指していきたいと思います。
またLLM開発は大規模な学習が必要なので、1つのモデルを作るのに数ヶ月~数年など膨大な時間がかかるため失敗が許されないシビアな開発です。開発自体に関するノウハウもまだ少ないので、積極的に外部にも共有ができればと思います。
ほかにも、スーパーコンピューター「富岳」を使った東京工業大学や富士通などが進めるLLM開発プロジェクトに当社も連携を検討していますが、こうした取り組みや、アカデミアと一緒にLLMに関する共同研究などにも力を入れたいです。
毛利:ビジネスとしては、まずはLLMを活用し、既存サービスの精度上げに引き続き注力していきます。すでに社内の極予測AIや極予測TDにおける広告コピー生成などの機能において活用を進めていますが、広告以外の当社サービス・・・医療やチャットボットなどにおいても応用が始まっています。
また今後は、他の企業と連携して業界に特化した独自データを学習させた「業界特化型のLLM構築」を行うことで、これまでの既存生成AIサービスでカバーできなかった専門用語/専門知識に強いLLMを構築し、それを日本に還元していく・・というような取り組みも行いたいと思っています。LLMをベースに、幅広いビジネス展開がまさに始まろうとしています。
ー LLMは、サイバーエージェントの競争力の源泉になり得る、と。
毛利:広告領域では間違いなくそうなりますね。今後は、その使い道を広げていくことが大事だと思っています。
石上:ここ半年で起きた「ChatGPTモーメント」のような時代の波は、数年のうちにまた起きると思っています。 そこに太刀打ちできるAI開発の体制を作っておくことが大事で、それが会社としての競争力にも繋がるのではないでしょうか。
ですがそれを自社だけで抱えるのではなく、多くの企業・アカデミア・国と連携しながら、日本全体の技術力向上に貢献できればと思います。
この記事をシェア
公式SNSをフォロー
記事ランキング
-
1

「目標はセンス」を、集合知に。新設「ゴールデザイン室(GD室)」が目指す目...
「目標はセンス」を、集合知に。新設「ゴールデザイン室(GD室)」が目指す目標設計の科学
「目標はセンス」を、集合知に。新設「ゴールデザイン室(GD...
-
2

マネージャーの葛藤に寄り添う。新設「マネージャーエンパワーメント室(ME室...
マネージャーの葛藤に寄り添う。新設「マネージャーエンパワーメント室(ME室)」が推進する伴走と共創による組織づくり
マネージャーの葛藤に寄り添う。新設「マネージャーエンパワー...
-
3

「Abema Towers(アベマタワーズ)」へのアクセス・入館方法
「Abema Towers(アベマタワーズ)」へのアクセス・入館方法
「Abema Towers(アベマタワーズ)」へのアクセス・...
-
4

全社のAI活用レベルを可視化して底上げする、サイバーエージェント流「AI番...
全社のAI活用レベルを可視化して底上げする、サイバーエージェント流「AI番付」とは
全社のAI活用レベルを可視化して底上げする、サイバーエージ...
NTTドコモの顧客体験を変革する、サイバーエージェント流UI/UX戦略

数千万人のユーザー基盤を持つ国内最大規模の通信キャリア、NTTドコモ(以下、ドコモ)。同社が今、時代の変化に合わせて推進している「顧客起点の事業運営」において、当社は現場への常駐を通じて深く並走を続けてきました。
本記事では、ドコモの猪俣氏と、当社の上野、野々山の対談を実施しました。社内の意識変革を促し、現在はプロダクトの継続的な改善・成長を共に担うパートナーへと関係性を発展させてきた両社。ドコモが持つ強固な事業基盤に、当社のプロダクトへの圧倒的な熱量と機動力を掛け合わせ、どのようにしてUI/UXを軸とした持続的な事業成長を共創しているのか。一つのチームとして挑んだリアルな変革の軌跡に迫ります。


