東京科学大学情報理工学院 岡崎直観教授に聞く、企業におけるAI活用・AI人材育成のあり方

サイバーエージェントでは、「生成AI徹底理解リスキリング」を2023年11月より社内向けに開始し、全社的なAI人材育成を強化してきました。当リスキリングでは、対象を全社員・エンジニア・機械学習エンジニア/データサイエンティストの3つの階層に分け、育成プログラムを実施しています。
先日実施した機械学習エンジニア/データサイエンティスト向けプログラムでは、2ヶ月にわたって各講師による講義やハンズオン、ケーススタディを行った後、特別講義として自然言語処理の第一人者である東京科学大学情報理工学院 岡崎直観教授に登壇いただきました。特別講義終了後は、参加者から多くの質問が飛び交い、当社社員にとって非常に有意義な機会となりました。
こちらの記事では、当リスキリングプログラム責任者 友松がインタビュアーとなり、岡崎教授が開発を進める大規模言語モデル「Swallow」についてや企業におけるAI活用、AI人材育成のあり方について伺いました。
Profile
-

岡崎直観氏
東京科学大学情報理工学院情報工学系 教授
産業技術総合研究所 招聘研究員
国立情報学研究所 科学主幹
東京大学大学院情報理工学系研究科・特任研究員、東北大学大学院情報科学研究科准教授を経て、2017年東京工業大学(当時)情報理工学院教授に着任。実社会で役に立つソフトウェアやサービスを意識しながら、人間のように言葉を理解し会話できるコンピュータの実現を目指し、研究と教育を展開している。 -

友松祐太
AI活用を推進する子会社 (株)AI Shift 執行役員CAIO
2018年新卒入社。コールセンター向けのプロダクトである、AI Messenger Chatbot/Voicebot/Summaryおよび生成AIを活用した企業の業務改善プロダクトであるAI Workerの開発に従事。データサイエンスチームリーダーとして音声対話やテキスト対話ロジックの研究開発、大学との産学連携、データの可視化などに取り組んでいる。
日本語に強い大規模言語モデル「Swallow」のレシピに迫る
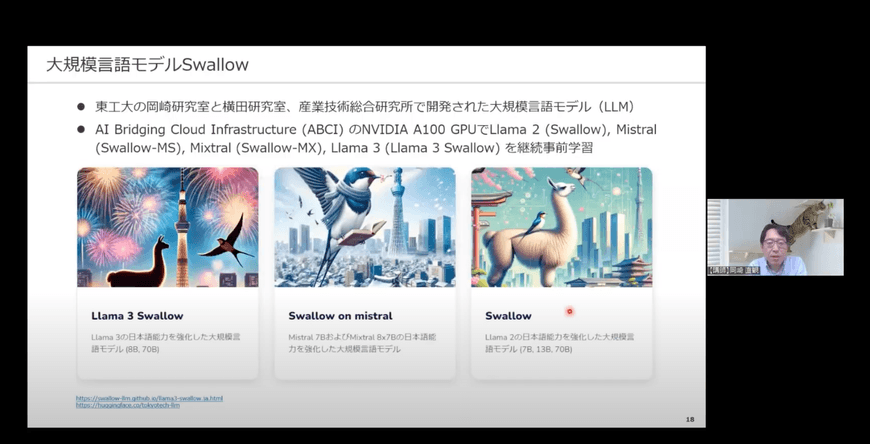
友松:岡崎先生の研究室では、横田理央教授らの研究チームと国立研究開発法人 産業技術総合研究所(以下、産総研)と共同で日本語に強い大規模言語モデル(以下、LLM)「Swallow」を開発していらっしゃいます。大学の研究室が独自にLLMを開発するというのは非常に珍しいことだと感じました。
岡崎氏:昔から自然言語処理の研究をしており、以前は自動要約研究の一環として、新聞社と共同で新聞記事の見出しを生成するツールを開発しました。5年以上前の取り組みですが、実際に現場で使えるほどの精度に仕上がりました。
その後LLMが登場した際に、実際に自分たちで作ってみなければ、賢い人工知能を実現するコアの部分が分からずに研究をすることになる危機感を感じました。開発の過程で、賢い人工知能を作るには何が必要か、そのレシピを知ることができると考えたからです。そんな中で横田先生からお声かけいただき、横田研究室で高性能計算(HPC)を、岡崎研究室は学習データの準備やモデルの評価を中心に担当することになりました。また、産総研に提供して頂いた計算環境(ABCI)を活用し、Llama 2をベースに「Swallow」を開発しました。
大学の研究室単位で密に連携してLLMを開発している事例は他にはありません。「Swallow」のようにコンパクトな体制で開発すると小回りが利きますし、アイディアをすぐに実行に移せる点にメリットを感じています。

当社エンジニア向けの特別講義では、独自にLLMを開発したからこそ得られた知見を展開
岡崎氏:今回の講義では「大規模言語モデルとSwallowの現状と展望」と題し、LLMを開発しているからこそ分かるその仕組みや開発する上で気をつけている点、また日本語に強いLLMを開発することの意義等についてお話させていただきました。様々なLLMがありますが、自分たちで評価・検証を行い、人工知能の賢さについて考察を深めることがなぜ大切なのか、この講義で理解していただければと考えています。
友松:実際にLLMを開発していらっしゃる岡崎先生だからこそ分かる知見を共有いただき、ありがたかったです。サイバーエージェントでも独自の日本語LLMを開発していますが、その知見を細部にわたって知る機会がなかなかないため、LLMを開発する上での苦労を直接伺えたのは多くのエンジニアにとって有意義な機会だったと思います。
当社のみならず、日本語に強いLLMを開発する企業が増えていますが、どんなことが求められるとお考えでしょうか?
岡崎氏:LLMには色々なサイズがあり、世界的な大企業が開発するものでは1000億級を超えるモデルが動いていることもあります。1つのモデルで全ての国の言葉・森羅万象を扱おうとする考え方もありますが、実際にビジネスで利用するLLMのサイズはせいぜい100億、最も使いやすいのは数10億パラメータ台でしょう。その場合、全ての言語や国の知識を1つのLLMに入れるのは現実的ではありません。日本語に関して使いたいのであればやはり日本語向けに強化したLLM、応用に特化したモデルの方がコストパフォーマンスが良いと考えます。日本で日本語に強いLLMを開発する意義というのは、日本で大切にされている言葉や文化、情報を把握したうえで、適切に応答できることです。
御社が、独自のLLMを開発されているのは本当に素晴らしいことだと感じます。LLMの開発というのは、データと計算資源があればできる、という簡単なものではありません。例えば、大量のテキストデータと計算資源で次の単語予測を学習するとベースモデルができますが、ベースモデルだけでは全く対話ができません。インストラクション・チューニングすることで初めて対話できるモデルになりますが、インストラクション・チューニングのためにどのような学習データを用意すればよいのか、汎用的に使える人工知能を開発するためにどのようなデータ作成・評価を行えばよいか、自明ではありません。自分たちでLLMを開発した経験があるかないかというのは大きな違いがあると思っています。開発経験があればLLMの特性を理解しているので、LLMの利用の勘所を把握しているでしょうし、オープンで性能の良いモデルの中から応用にそって最適なモデルを選ぶためのノウハウも持っていると思います。
友松:この1,2年で様々なLLMが出現したことで、データサイエンティストがバリューを発揮する場所が変わってきたと常々感じています。世界的な大企業の技術トレンドに乗るだけでは、急速な変革にただ振り回されることになりかねません。自分たちならではの強みを掛け合わせていくことが重要だと思います。
重要なのは、有り物の生成AIを良くするための工夫
友松:生成AIは社会全体に大きな変革をもたらしましたが、岡崎先生をはじめ自然言語処理の研究者における生成AIの立ち位置はどのようなものなのでしょうか?
岡崎氏:AIのトレンドでいうと、生成AIの前に2010年代に深層学習ブームがありました。音声処理と画像処理でブームが進行し、やがてそれらが自然言語処理にも移ってきました。その後、自然言語処理では機械翻訳モデルの研究が進展し、Transformer(Googleの研究者等が発表した深層学習モデル)が生まれました。それと同じような時期に画像処理の分野では敵対的生成ネットワーク(GAN)が出現し、画像生成やスタイル変換が実用的になりました。このように、AIが画像やイラストも描いてくれるという機運が高まってきたのが2010年代中頃のことです。
2020年頃に現在のLLMに近い規模のモデルが登場しましたが、当時のLLMは次の単語を予測するという昔ながらの言語モデルでありながら、汎用性が垣間見れることがあり、ある程度面白いことができるようになりました。その後拡散モデルが出てきて、画像処理の分野ではいよいよAIが人間を超えるクオリティのイラストを描ける可能性が高まりました。そしてChatGPTが登場し、自然言語の分野でも生成AIが本格的に使えるようになったと思います。
友松:私は2017年からチャットボットの開発に携わっていますが、当時の自然言語処理の技術として単語同士の演算ができることに衝撃を受けていました。
そこから10年経たずして、このような変化を遂げたことに大きな驚きを感じています。
一方で、生成AIへの大きな期待がある中で、期待値のズレも徐々に現れてきたと思います。特別講義の中で岡崎先生もおっしゃっていましたが、Gartnerが発表した「生成AIのハイプ・サイクル:2024年」では、生成AIは幻滅期に入っていくというお話がありました。生成AIにおいては、社会実装する上でまだまだ課題があると思いますし、これから5年、10年後に様々な技術の進歩がある中、企業としてどう社員のリスキリングを進めていくべきか、難しい課題だと考えています。
現在当社が取り組んでいる「生成AI徹底理解リスキリング」をはじめ、様々な企業がAI人材の育成を推し進めていますが、その点どのように考えていらっしゃいますか?また、育成にあたって外してはいけないポイントがあれば教えていただきたいです。

岡崎氏:AIや機械学習の人材は不足しているので、企業がサポートしてそれらの分野の人材を増やそうとするのは重要な取り組みだと考えています。生成AIにおいてはどんどん新しい技術が出てくるので、過去に学んだ基礎はもちろん大事なんですけれども、そこから常にキャッチアップしていくことが重要です。そういった点でも、企業がリスキリングのような取り組みを推進することは、日本の競争力を高めるうえでも大切だと考えています。
一方で、企業の上層部が生成AIの活用方法を無理やり考えさせるような進め方はうまくいくか分かりません。その代わり、現場や若手がボトムアップで思いついたアイディアは面白いものが多く、イノベーションをもたらす可能性があります。そのような土壌を醸成していくことが重要だと思います。
また、生成AIの使い方を理解するだけでは足りないとも考えています。今の生成AIは何かを入力すると何かが出力されますが、望む出力が得られないときどのように工夫するのか。入力を工夫するのか、モデルを変えるのか、モデルをチューニングするのか、そのためにデータを作るのかといった意思決定を、根拠をもって行えるようにすることも大切です。
友松:生成AIのように新たな技術が流行し始めたタイミングでは、それらを使うことが目的になるという現象はよくありますよね。例えば、生成AIでなくともできるタスクを無理やりやらせるといった事例です。生成AIを活用する機運が高まることは大事ですが、本質的な業務やお客様向けに利用する際にはより一層気をつけないといけません。できる限り打ち手の数を増やして、その中から必要に応じて最適の解決策を選択していく姿勢が企業には重要だと感じます。
最後に、この大きな変革の時代に、機械学習エンジニアやデータサイエンティストを目指す方々にメッセージをいただきたいです。
岡崎氏:生成AIの登場により、プログラムも、大学のレポートも聞けば書いてくれる時代になりました。そんな時代ではなぜ勉強する必要があるのか、目的を見失いがちです。もちろん調べるだけであれば生成AIに聞けば良いのですが、やはり我々人間は日々問題を解決していく必要がありますので、そのためにはこれまでに解決した経験や解決するための知識を頭の中からすぐ取り出せるようにしておく必要があります。
例えば、生成AIの助けを借りながらプログラムを書けることと、そのプログラムをデバッグできることは、難しさが全く違うと思います。デバッグできるようなスキルを身につけるためには、生成AIの間違いを指摘できるように自ら勉強する必要があります。
この記事をシェア
オフィシャルブログを見る
記事ランキング
-
1

NTTドコモの顧客体験を変革する、サイバーエージェント流UI/UX戦略
NTTドコモの顧客体験を変革する、サイバーエージェント流UI/UX戦略
NTTドコモの顧客体験を変革する、サイバーエージェント流U...
-
2

年間広告スポンサー数1,000社の「ABEMA」が西日本事業部を新設。なぜ...
年間広告スポンサー数1,000社の「ABEMA」が西日本事業部を新設。なぜ今、同エリアへ本格進出を果たすのか
年間広告スポンサー数1,000社の「ABEMA」が西日本事...
-
3

アニメ制作の新時代を切り拓く「CA Soa」 クリエイターと描く未来
アニメ制作の新時代を切り拓く「CA Soa」 クリエイターと描く未来
アニメ制作の新時代を切り拓く「CA Soa」 クリエイターと...
-
4

全社のAI活用レベルを可視化して底上げする、サイバーエージェント流「AI番...
全社のAI活用レベルを可視化して底上げする、サイバーエージェント流「AI番付」とは
全社のAI活用レベルを可視化して底上げする、サイバーエージ...
NTTドコモの顧客体験を変革する、サイバーエージェント流UI/UX戦略

数千万人のユーザー基盤を持つ国内最大規模の通信キャリア、NTTドコモ(以下、ドコモ)。同社が今、時代の変化に合わせて推進している「顧客起点の事業運営」において、当社は現場への常駐を通じて深く並走を続けてきました。
本記事では、ドコモの猪俣氏と、当社の上野、野々山の対談を実施しました。社内の意識変革を促し、現在はプロダクトの継続的な改善・成長を共に担うパートナーへと関係性を発展させてきた両社。ドコモが持つ強固な事業基盤に、当社のプロダクトへの圧倒的な熱量と機動力を掛け合わせ、どのようにしてUI/UXを軸とした持続的な事業成長を共創しているのか。一つのチームとして挑んだリアルな変革の軌跡に迫ります。


